Sunday, June 16, 2024
Tuesday, June 11, 2024
Normalization in DBMS
Problems: Redundancy
Different kinds of Normal Forms:
1NF, 2NF,3NF etc
Data Modelling
Star Schema
Star schemas denormalize the data, which means adding redundant columns to some dimension tables to make querying and working with the data faster and easier. The purpose is to trade some redundancy (duplication of data) in the data model for increased query speed, by avoiding computationally expensive join operations.
In this model, the fact table is normalized but the dimensions tables are not. That is, data from the fact table exists only on the fact table, but dimensional tables may hold redundant data.
Resources: https://www.databricks.com/glossary/star-schema
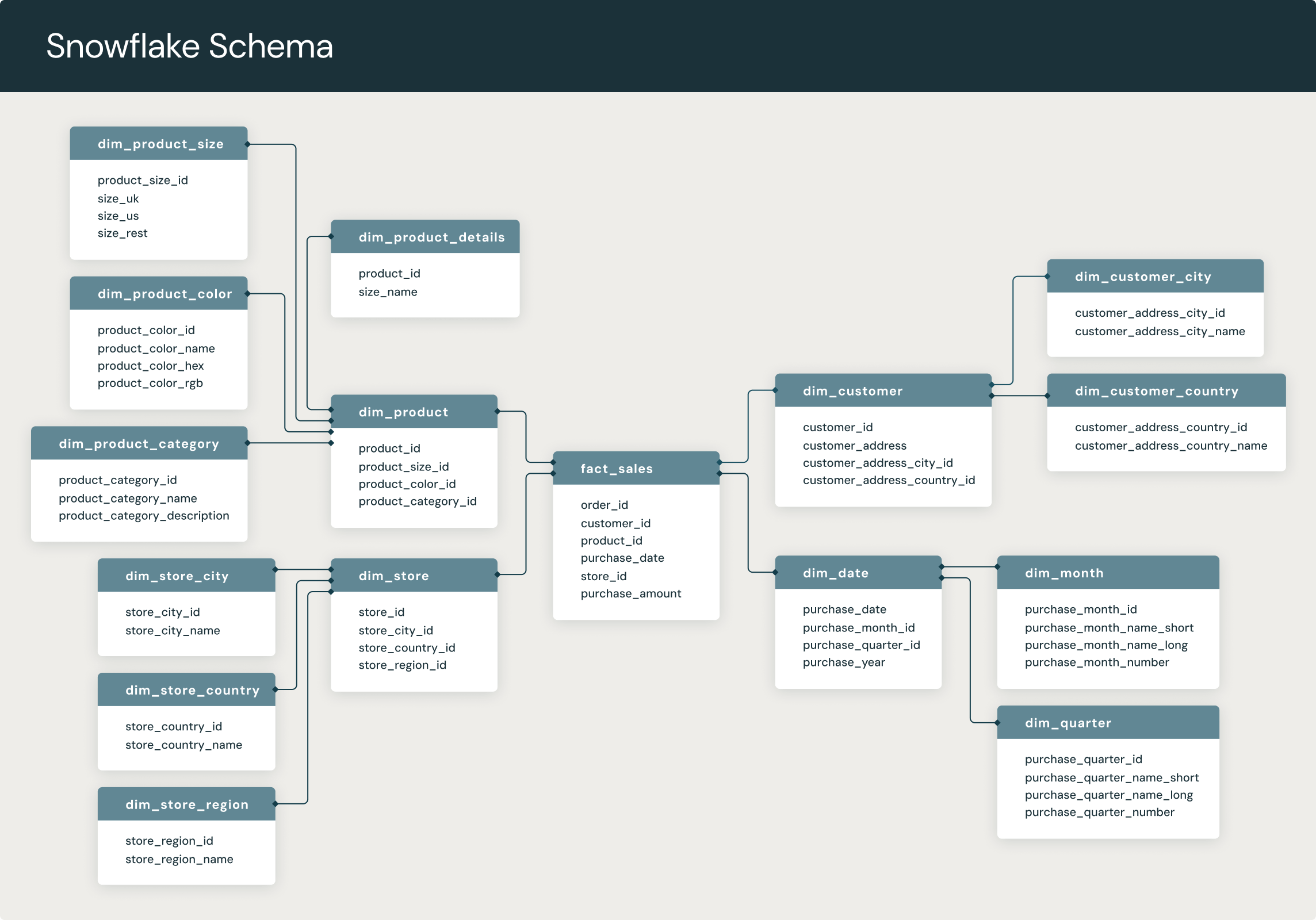
snowflake schema:
A snowflake schema is a multi-dimensional data model that is an extension of a star schema, where dimension tables are broken down into subdimensions. Snowflake schemas are commonly used for business intelligence and reporting in OLAP data warehouses, data marts, and relational databases.
In a snowflake schema, engineers break down individual dimension tables into logical subdimensions. This makes the data model more complex, but it can be easier for analysts to work with, especially for certain data types.
It's called a snowflake schema because its entity-relationship diagram (ERD) looks like a snowflake, as seen below.
Monday, June 10, 2024
Database Architecture
References: https://www.youtube.com/watch?v=9ToVk0Fgsz0
ETL Design Patterns
Data Governance
- Improved Data Management
- Provide meaning and quality of data, Improved Data Quality
- Regulatory, more consistent Compliance
- Reduced costs and Increased Value.
- Single source of Truth.
- Establishing Data ownership & Accountability
Data Lineage
Data Modeling
Normalization is the method of arranging the data in the database efficiently. It involves constructing tables and setting up relationships between those tables according to some certain rules. The redundancy and inconsistent dependency can be removed using these rules in order to make it more flexible.
There are 6 defined normal forms: 1NF, 2NF, 3NF, BCNF, 4NF and 5NF. Normalization should eliminate the redundancy but not at the cost of integrity.
- Normalization is the technique of dividing the data into multiple tables to reduce data redundancy and inconsistency and to achieve data integrity. On the other hand, Denormalization is the technique of combining the data into a single table to make data retrieval faster.
- STAR Schema, Snowflake Schema comes into Picture in this case.
What's the Difference Between a Data Warehouse, Data Lake, and Data Mart?
How to choose between star and snowflake schemas?
How to create a star schema?
Data lake vs. Data warehouse
What is the difference between a data lake and a data warehouse?
A data lake and a data warehouse are two different approaches to managing and storing data.
A data lake is an unstructured or semi-structured data repository that allows for the storage of vast amounts of raw data in its original format. Data lakes are designed to ingest and store all types of data — structured, semi-structured or unstructured — without any predefined schema. Data is often stored in its native format and is not cleansed, transformed or integrated, making it easier to store and access large amounts of data.
A data warehouse, on the other hand, is a structured repository that stores data from various sources in a well-organized manner, with the aim of providing a single source of truth for business intelligence and analytics. Data is cleansed, transformed and integrated into a schema that is optimized for querying and analysis.