Kubernetes is a Container Orchestration tool.
Multiple containers do run in worket nodes.
Features:
- High Availability
- Scalability
- Disaster Recovery
Basic Architecture:
It's basic Architecture contains Pods & Containers
1 Pod per Application, each pod contains 1 or more containers
Typically, 1 pod contains 1 container, however in cases when an application needs to access more than 1 resource like Database is in 1 container, messaging system is in another Container etc.
Why Spark on Kubernetes?
1. Multiple kinds of applications can run with each having it's own library dependency in the form of containers.
Eg: In a cluster the below different kinds of applications can run simultaneously having their own library dependency.
- Spark Applications can run in their own container.
- ML Applications can run in a separate container. ML Libraries need not be installed in the cluster.
2. Spark cluster is a shared resource and if an upgrade needs to happen from Spark 2.0 to Spark 3.0 all the applications needs to be migrated. Incase of Kubernetes, only the applications those need to be upgraded can upgrade their dependencies and can run in their independent containers.
AWS EKS
The following diagram shows the two different deployment models for Amazon EMR.
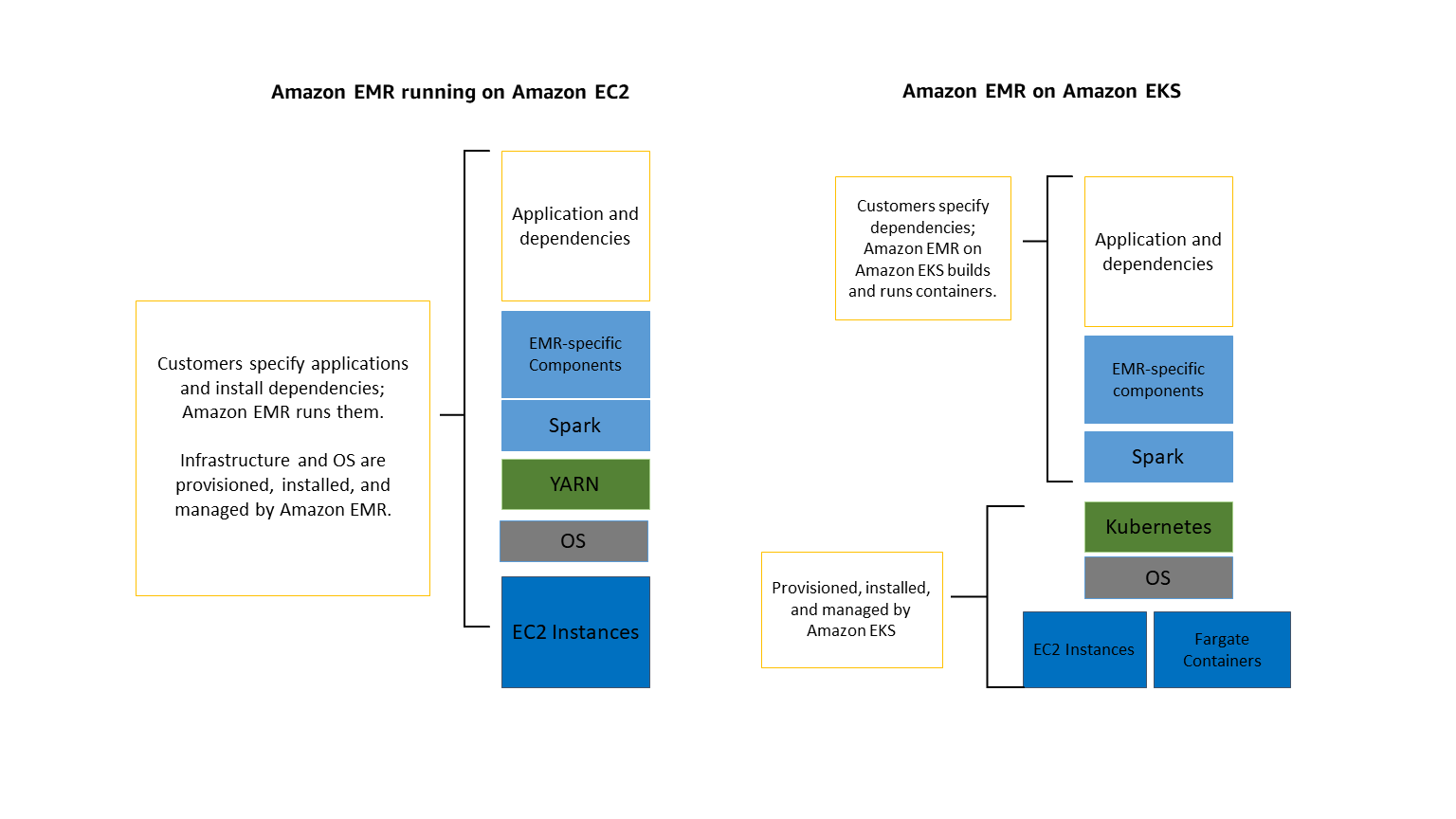
Job Submission Options:
- AWS Command line Interface
- AWS Tools and AWS SDK
- Apache Airflow
Sample command to Launch a PySpark job on AWS EMR on EKS
aws emr-containers start-job-run \
--virtual-cluster-id <EMR-EKS-virtual-cluster-id> \
--name <your-job-name> \
--execution-role-arn <your-emr-on-eks-execution-role-arn> \
--release-label emr-6.x.x \
--job-driver '{
"sparkSubmitJobDriver": {
"entryPoint": "s3://<your-s3-bucket>/scripts/your_pyspark_script.py",
"entryPointArguments": ["arg1", "arg2"],
"sparkSubmitParameters": "--conf spark.executor.instances=2 --conf spark.executor.memory=2G --conf spark.driver.memory=1G"
}
}' \
--configuration-overrides '{
"applicationConfiguration": [
{
"classification": "spark-defaults",
"properties": {
"spark.hadoop.fs.s3a.impl": "org.apache.hadoop.fs.s3a.S3AFileSystem",
"spark.kubernetes.container.image": "<your-custom-emr-on-eks-image-uri>"
}
}
],
"monitoringConfiguration": {
"s3MonitoringConfiguration": {
"logUri": "s3://<your-s3-bucket>/logs/"
},
"cloudWatchMonitoringConfiguration": {
"logGroupName": "<your-cloudwatch-log-group-name>",
"logStreamPrefix": "<your-log-stream-prefix>"
}
}
}'
--virtual-cluster-id: The ID of the virtual cluster registered with your EKSReference: https://www.youtube.com/watch?v=avXbYBPzpIE&t=649s

